Abstract
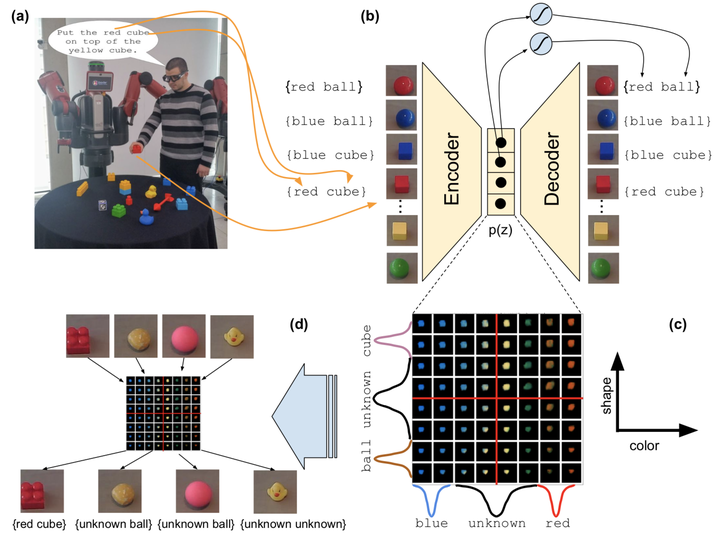
Effective human-robot interaction, such as in robot learning from human demonstration, requires the learning agent to be able to ground abstract concepts (such as those contained within instructions) in a corresponding high- dimensional sensory input stream from the world. Models such as deep neural networks, with high capacity through their large parameter spaces, can be used to compress the high-dimensional sensory data to lower dimensional representations. These low-dimensional representations facilitate symbol grounding, but may not guarantee that the representation would be human-interpretable. We propose a method which utilises the grouping of user-defined symbols and their correspond- ing sensory observations in order to align the learnt compressed latent represen- tation with the semantic notions contained in the abstract labels. We demonstrate this through experiments with both simulated and real-world object data, showing that such alignment can be achieved in a process of physical symbol grounding.
Yordan Hristov
PhD student
PhD student at the Robust Autonomy and Decisions group, part of the Insitute for Perception, Action and Behaviour at the University of Edinburgh. I am supervised by Dr. Subramanian Ramamoorthy and Prof. Alex Lascarides.